

Get the Popular Science daily newsletter💡
Breakthroughs, discoveries, and DIY tips sent every weekday.

For decades, preservationists charged with digitizing rare books have faced an ironic challenge. The whole point of scanning these often one-of-a-kind objects is to keep the delicate manuscripts from harm. To do that, however, required a much more hands-on approach.
One of the first solutions was to simply place a tome in a book cradle, then photograph each individual page. In later years, archivists increasingly relied on more advanced top-down document camera arrays. Even today, the digitization process is frequently tedious and time-consuming work—and that’s where specially designed robots come in handy.
After two years of research, archivists at the University of Tulsa’s McFarlin Library recently decided to try out a machine called the Treventus ScanRobot 2.0. Built in Austria, the bot does exactly what its name implies—it autonomously scans and digitizes manuscripts. But whereas it might take a single librarian days or weeks to scan a single book, the ScanRobot 2.0 can handle up to 2,500 per hour. It’s not sacrificing safety for speed, however. The setup relies on a unique toolkit to ensure it digitizes a book quickly, but with the least amount of direct contact possible.
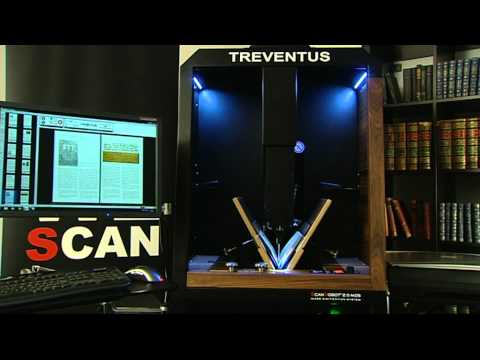
First, a camera housed in a wedge-shaped case descends down into a book’s center margin, also known as the gutter. Small holes in the triangular plate then generate a vacuum to softly pull pages to either side of the camera’s prism. The imaging unit next ascends up again while scanning both pages simultaneously. Once completed, the vacuum switches off and air nozzles emit a small puff of air to turn the pages. The whole process then repeats again and again, until a book is finished.
But purchasing a ScanRobot 2.0 doesn’t mean the librarians can simply flip it on and leave the room. The library’s department director and rare books cataloger both trained for a week to become certified book robot operators. One of them is always at the control panel whenever the robot is in use to monitor its progress, adjust settings in real-time, or pause its work altogether.
“Our assessments show that around 64,000 of our books are out of copyright and could be scanned and uploaded, and more books join the public domain every year,” Kunz explained in a university profile earlier this year. “There will always be books to make available for our students and scholars.”

More deals, reviews, and buying guides
Source link



